


Using data analytics to improve HR’s strategic role in an organization is both exciting and terrifying at the same time. Many HR professionals have limited experience with data analytics and just don’t know where to start. If this describes you, then this playbook is the ticket to help you master the basics and to get you started on building an HR data strategy.
This playbook will help you achieve the following goals:
- To identify and catalog your organization’s HR data assets;
- Build an HR Data Strategy;
- Manage your HR data assets;
- Increase the usability of your data assets; and
- Help employees and leaders make better decisions by accessing and analyzing HR data.
While many of these concepts may seem difficult at first, when you break them down into their component part, it’s easy to understand what’s happening. So, buckle up and get ready to get build your data-ninja skills. And, remember your core purpose – help your organization make data-driven decisions about its most valuable resource, its people!
“Companies that have not yet built a data strategy and a strong data-management function need to catch up very fast or start planning for their exit.”
– DalleMule and Davenport
Dear HR Professional,
Using data analytics to improve HR’s strategic role in an organization is both exciting and terrifying at the same time. Many HR professionals have limited experience with data analytics and just don’t know where to start. If this describes you, then this playbook is the ticket to help you master the basics and to get you started on building an HR data strategy.
So, why is data analytics important to HR in the first place? Data, such as employee retention rates, engagement levels, or regional sales numbers, is of limited value until it has been integrated with other data points and transformed into insights that can illuminate problems and guide decision-making. Data makes us smarter and reduces our tendency to rely on our “gut instincts.”
Within analytics, we focus on two key objectives: (1) reporting, and (2) analysis. Reporting translates raw information into tables, charts, and lists – with this information most often being presented on dashboards. For example, a dashboard can help a tire company know how many tires they have in inventory, and at what rate they are selling them. Reporting also helps companies monitor their business activities, and it can alert them when something slips from the norm.
The analysis goes one step further and transforms information into business insights, which take the form of predictors, relationships and associations, correlations, drivers, trends, norms, and benchmarks. Analysis answers questions by interpreting data at a deeper level, which helps strategic thinkers make better and more informed business decisions. For example, returning to our tire company example, analysis answers the question as to why the company sells more tires in New Jersey than in Florida – its’ because people buy snow tires and because roads are hard to maintain in cold-weather locations. This insight can help leaders know what to do next – open more stores in cold parts of the country.
This playbook will help you achieve the following goals:
- To identify and catalog your organization’s HR data assets
- Build an HR Data Strategy
- Manage your HR data assets
- Increase the usability of your data assets
- Help employees and leaders make better decisions by accessing and analyzing HR data
While many of these concepts may seem difficult at first, when you break them down into their part, it’s easy to understand what’s happening. So, buckle up and get ready to build your data-ninja skills. And, remember your core purpose – help your organization make data-driven decisions about its most valuable resource, its people!
Sincerely,
DecisionWise
Key Concepts and Vocabulary
Before we dive into the basics of how to build an HR data strategy, let’s cover some key concepts and vocabulary.
EMPLOYEE DEMOGRAPHIC DATA
Employee demographics are categories that help us describe and define the people in our organizations. Demographics are the kings and queens of HR data; they are people attributes, and they include identifiers such as birthdate, preferred gender, work location, race or ethnicity, tenure, work transfers, previous positions, home addresses, education levels, current and past skills, FSLA status, and many, many more. You may only be using 4-5 demographics right now, or your system might be more robust, and you are collecting and managing 20 or more demographics. As we discuss below, the more demographics you track, the greater your ability to use analytics to predict, and possibly shape, future outcomes.
In technical jargon, demographic data is called quantitative data. Quantitative data is data expressing quantity, amount, or range. In essence, quantitative data helps us define something. Human Resources Information Systems (HRIS) are phenomenal at gathering demographic data, but paper intake forms do the same thing. It’s just that paper forms require you to translate the information printed on the forms into data that is stored digitally so that it can be sorted and analyzed.
TIP: Organizations face an interesting challenge when collecting demographics. Employees do not want to feel they are being spied on; collecting too much data can feel intrusive and generate suspicion and distrust. No organization wants to be perceived as “big brother” to their employees.
EMPLOYEE PAB DATA
PAB stands for perceptions, attitudes, and beliefs. This is the data you obtain by asking employees questions through surveys – such as employee engagement surveys, pulse surveys, sentiment tools, etc. This type of data can be either quantitative or qualitative data. Qualitative data doesn’t tell me how many yo-yos (quantitative) I have; instead, qualitative data tells me how my customers describe the yoyos I sell.
STRUCTURED DATA
Structured Data is data that has been through an organizing process. For example, if you have put data into a spreadsheet, then you have turned it into structured data. Data stored in a software program is usually exported in a structured format through what we call a flat file or CSV file (comma-separated values). Essentially the export is a digital table that we can import into other systems for further analysis.
UNSTRUCTURED DATA
Unstructured Data is information that has been collected but has not yet been organized, sorted, or cataloged. Or, it is data that has been organized for one purpose but has not been organized for the purpose we want or need. All data is either structured or unstructured. A backup copy of an employee’s emails is unstructured data. The emails haven’t been organized by size, date, recipient, subject matter, etc.
EMPLOYEE FINGERPRINT DATA
This is data that has been collected through an employee’s interactions with the organization and its various digital systems (i.e., everywhere we see an employee’s digital fingerprint). For example, we can look at an employee’s calendar to see how many meetings they attend each week. Your HCM can tell you: how many PTO days someone has used and when. How many e-mails are typically sent in July as opposed to October? What trainings have been completed over the last 18 months? At what time was an employee’s ID badge first scanned by the front door?
Sometimes, fingerprint data is called data exhaust, which is unstructured data that is an output from the various software and hardware platforms that power an organization. In most cases, employee fingerprint data/data exhaust is unstructured because it has not been organized for the types of analyses we want to perform.
DATA STORAGE
To analyze data, you must first find it and store it. Data is typically stored in one of three ways:
DATABASE – a database is a place where data is stored and organized. Databases make it easy for a software application to retrieve information or save a file because the database has a predefined structure. For example, an HR database typically assigns a new employee a unique ID, and then it knows to save all sorts of information about that employee, such as name, address, age, etc., about that unique ID. This type of database is called a relational database because it is a database that is structured to recognize relationships between stored items of information.
TIP: If the information is in a table, then it is a relational database. Many spreadsheets are simple relational databases. Data that has been put into a database format is the easiest to access and analyze. Think of it like a large storage cube from IKEA. Each piece of information has its own little place to live.
STORAGE DRIVE – these are devices like a USB drive, SD card, or hard drive. It’s a place where digital information is stored. Think of a storage drive as a virtual storage container where you place information for safekeeping, and it accepts all types of files: PDFs, images, videos, documents, etc. Storage drives have directories (a list of what’s kept where), which can help you locate the files you put on the drive. Storage drives can be physically managed by you, or they can be hosted in the cloud where they are kept and maintained in large, secure data centers. Even though drives have directories, they are not like databases. They simply tell you where something is, but they can’t necessarily talk to a software program and send that program a piece of information upon request.
DATA LAKE – this is a storage drive on steroids, and data lakes are always hosted in the cloud. Just throw anything into the lake for safekeeping, and you don’t even have to organize where you put it. Data lakes are smart enough to categorize and organize that data for you. The idea with a data lake is to grab everything you can, like your digital exhaust, and have it flow into the lake. Later, we can go back and start analyzing the information, but at least we have our data in a single, known location. Data lakes are sometimes called Data Warehouses.
DATA CLEANING
Data cleaning (sometimes called “data munging” or “data wrangling”) takes various pieces of data and ensures we are using the same names for the same concepts. For example, one file might call a wheeled machine used for human transport an “automobile” and another data file might use the term “car.” To make data analysis possible, things that are the same need to use the same name, or at the very least, we need to tell our systems that “automobile” and “car” represent the same thing.
Another example involves the codes we use in our databases. Someone who is listed as a team leader might be identified in the database by “L,” “LDR,” “Leader,” “TL,” “Team Leader,” “MGR,” “M,” or “Manager.” Cleaned data changes the data to use a single code or to use a translator that tells our systems that L and LDR are the same things. Schema crosswalks are tools we use in data cleaning. A schema crosswalk is a table that shows equivalent elements (or “fields”) in more than one database schema. It maps the elements in one schema to the equivalent elements in another schema. Using a crosswalk is what we call data mapping.
Data cleaning also involves normalizing. This is important with qualitative data that use different scales. If one survey asks survey participants questions using a 10-point scale and another survey uses a 5-point scale, we need to adjust the scores to use the same scale. Otherwise, a “superior” 5 on one survey will become an “average” score on a survey that used a 10-point scale.
DATA CONNECTORS
Data connectors are ways we connect two or more data sources so that data files are updated with new additions, deletions, etc. Data connectors require mapping the two data sources, so they talk to each other about the same concepts. Making software systems “talk” to each other can be difficult, especially when software programs may have been built in different decades and use different computer programming languages and methodologies.
DATA MODEL
The data model is a system or process that mandates how data is to be stored, identified, tabulated, collected, and connected so that software applications and analytics teams can access and move data as needed.
STATISTICAL ANALYSES
Statistics is a branch of mathematics that deals with probability. Statistics do not tell us what will happen, it tells us what is most likely to happen. Statistics helps organize and study data so that we can see associations between two pieces of information. For example, statistical analyses help us find correlations. A correlation is a relationship between two pieces of data, and statistical formulas tell us if that relationship is strong or weak. For example, when do people wear name badges? Do they wear them at a fine restaurant (weak)? What about a tradeshow or convention (strong)?
ALGORITHM
The algorithm is a process or set of rules to be followed in calculations or other problem-solving operations. Algorithms tell computers what to do with the data; they are a set of instructions to be followed. A simple algorithm is a decision tree. Employees whose last names begin with W should line up at door X. Employees with last names beginning with B should line up at door Y. This process of sorting employees is an algorithm. In modern software, algorithms are the backbone of any computer program.
DATA INTEGRITY OR DATA MANAGEMENT
This concept covers how data is kept secure and unpolluted. Policies should define who can access or change data and under what circumstances. Also, is the data protected from prying eyes, and is a backup copy available in case of a problem? How long will we keep our data and what is the process for destroying data?
Data integrity also asks us to identify our single sources of truth. Here is an example to clarify. Let’s say your employee roster resides in your HRIS and within your payroll system. Which is your single source of truth? The payroll system may contain individuals who are not employees but are being paid for some other reason.
Hence, your HRIS should be your single source of truth for your employee roster. Data integrity/data management involves deciding on what data sources will be used as single sources of truth or which will be part of a larger cadre, what we call multiple sources of truth.
MACHINE LEARNING (ML)
Machine learning uses powerful computer processing to take a set of data points and then run scenario after scenario using the different ways those data points might be combined to find which relationships are the most significant. It’s like having someone consider each scenario by hand, but since it’s a computer, it can process each scenario in nanoseconds and then learn what works and what doesn’t. For example, it’s like finding a single rabbit in a field of ten thousand rabbit holes. Machine learning is where the software starts exploring rabbit hole after rabbit hole and then quickly learns after sampling hundreds of holes, which are most likely to house our rabbit. Machine learning acts like a virtual shortcut to help us find answers that would take a great deal of time and effort.
ARTIFICIAL INTELLIGENCE (AI)
As noted, machine learning uses the raw computing power of modern processors to run thousands and thousands of data models to account for a vast number of possibilities. Yet, machine learning is still reliant on a predefined set of instructions, or algorithms. Artificial intelligence goes one step further by letting the software application make its own decisions based on what it experiences as it conducts the modeling. Thus, in our case, an AI software program starts to decide which models it will use, how many variations it will run, what variables it will include, etc. AI can accomplish this monumental task because it can run through scenario after scenario very quickly and “learn” what is optimal. AI is essentially machine learning on steroids.
How The Analytical Process Works
Now that you’ve become familiar with the basic concepts, the next step is to understand how we process data to find insights and move from reporting to analysis. As touched upon earlier, our goal is to take data and find meaningful relationships between the various data points. These relationships are the building blocks in finding insights, such as the relationship between a person’s commute length and how likely they are to quit their job. If we have no sense of these relationships, our decision-making is limited.
However, if we know that employees who never have a one-on-one with their manager are more likely to quit, then we can use that insight in deciding who we will promote (promote those that will hold one-on-one meetings).
By exploring large amounts of data, we are moving away from guesses and “gut instincts” into a realm where we gather as many relationships as possible to help us see how behaviors and actions are interconnected. For example, is employee productivity greater or less during the months in which World Cup soccer is played?
This graphic shows how the data gathering process might flow in a common HR environment.
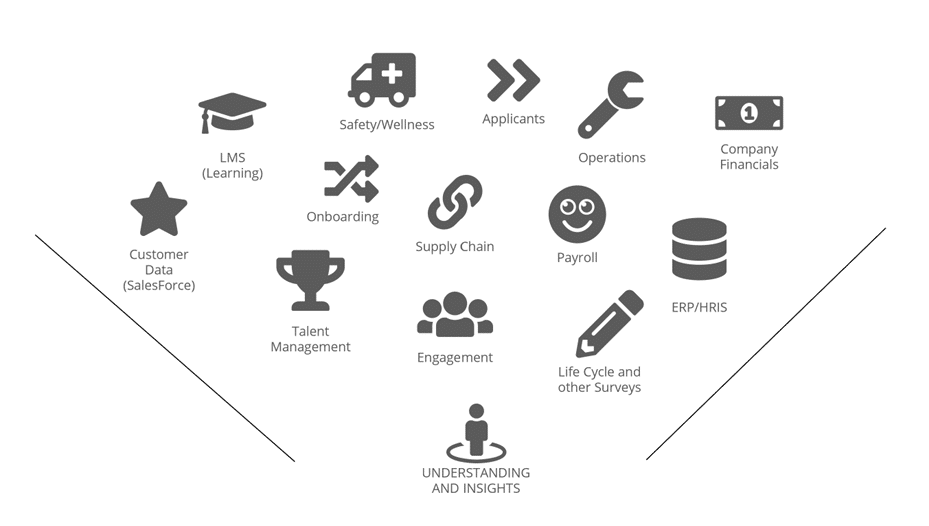
Data, however, doesn’t just flow naturally into understanding and insights. It must be transformed and studied. Studying and transforming data is the heart of data analytics. This graphic shows you a typical progression when performing data analysis.

The analytical process begins with organizing data so we can study it. We then look for basic relationships through charts and tables. For example, tables show basic relationships, such as the number of women in an organization’s software engineering department.
Once we have collected and sorted through the more common relationships we might find, we further refine them (winnowing or narrowing). For example, we may learn from a table that we have more female employees than male employees in HR. Is that difference meaningful or is the difference simply a product of chance? That’s where statistical analyses come into play. Statistics help us answer that question. If the difference is not subject to change, then we can start asking why that difference exists. For example, do we often recruit from women-only colleges?
Once you have mastered statistical analyses, you can then move into more advanced models that help increase our confidence in the relationships we have found and maybe help us see additional relationships that have yet to be discovered. This is when we start using machine learning and AI. With machine learning and AI, the more data points we can consider, the better the results. We can even begin to predict what might take place. Here’s a simple illustration. If we have a very good understanding that employees who possess a certain educational background succeed in our organization, we can use that insight to predict who might succeed during the next round of promotions.
As mentioned, to make analytics predictive, we need a lot of data points. Here’s a case study to explain what we mean. If we only track age, gender, and work location, then we really can’t predict which employees will leave the organization after 1 year because we don’t have enough relationships to explore. Maybe women leave more often, but we don’t know what’s causing that to occur because we don’t have enough data points to consider all the possibilities. But, if we are tracking commute time, job tenure, job shift, tenure with manager, age, last promotion date, pay grade, etc., we then have a lot more possibilities to think through.
To summarize, the following graphic explains how the analytical process works as we advance through our tools.
DESCRIPTIVE ANALYTICS
What happened?
DIAGNOSTIC ANALYTICS
Why did it happen?
PREDICTIVE ANALYTICS
What will happen?
PRESCRIPTIVE ANALYTICS
How can we make it happen?
Your HR Data Strategy
Now that we have spent some time with the underlying theory, let’s talk about tactics. What do you need to do to start tapping into the power of HR analytics? You must first start by building an HR data strategy.
Why is an HR data strategy necessary? In their essence, organizational data sources should not be viewed as a mere byproduct; instead, they should be treated as assets that can significantly benefit the organization. The right data strategy ensures the proper management and utilization of these important data assets. Also, without a strategy, your efforts will be disorganized and less effective.
Consider the following observations:
- Many projects require access to the same data content. Unfortunately, if there is no coordination to prevent overlapping, resources will be
- Without a data strategy, there is no data sharing, no data reuse, nor are there economies-of-scale activities to simplify or reduce the cost of data movement and development.
- A well-developed data strategy prevents business users from accessing common data across separate applications.
- Finally, and maybe most importantly, data names and formatting will remain consistent across uses and Standardized data prevents inconsistencies across reports because source data does not vary from application to application, and from report to report.
A data strategy is a key to creating standards, promoting collaboration, and planning for the reuse of data assets and capabilities. Historically, IT has been focused primarily on how to store data and keep it safe. Today, we are interested in how we access data, transform it, learn from it, use it, and deploy the information we have gathered to move the organization forward.
Specifically, from an HR perspective, there is an additional reason why HR needs a data strategy. HR is behind the other business functions in its use of data to enhance decision-making and predict outcomes. So, HR needs a plan to catch up, and quickly.
At its core, a data strategy contains the following basic elements; although there are other important components to consider as well.
- Identify
- Prioritize
- Capture
- Store
- Manage/Govern
- Analyze
What’s Next?
Here is a recommended roadmap to follow over the next several months as you work on building your HR data strategy.
- Start by identifying your HR data We call this making a data balance sheet. Where are the assets located? Who will you need to work with to access these assets (who are the data stewards)? Don’t forget to classify the data based on legal requirements and sensitivity. For example, do you store medical information? One last point – make sure you understand the formats for how data is stored so that you can make your various data sources talk to each other.
- Define your ethics and goals. What will be your guiding principles? When will your track something and when won’t you? What legal or ethical duties do you owe your employees? Do you need consent from your employees to gather a certain type of information? Draft an HR analytics ethics policy.
- Start learning more about data security and Forge relationships with technical people in your organization. Learn what it will take to protect your HR data and how you can keep that information private and secure. Discover and tap into the chain of command for data security and privacy.
- Work with technical partners to create data management policies that are specific to your HR data Where will you store the data? Who should review your actions and policies? What do you do with redundant systems? How long will you keep the data, etc.? What are your data flows (start building a data map)?
- Determine how you will capture and store your HR data. Set your data access policies – who can access data, when, where, and under what conditions? Who is going to clean the data? What mapping and cross-walking need to take place?
- Finally, begin to increase data literacy within HR, and possibly, within your organization at large. What more do you personally need to learn? What courses or events are available for your team? Should you consider a certificate program in data science, or can you find a course on Udemy or Coursera?
As your work on these recommended steps, more and more possibilities and tasks will unfold before you. Again, this is just the starting point. Like an iceberg, much is hidden that needs to be explored and uncovered.
Ethical Considerations and Conclusion
The possibilities with good data analytics are endless, but you need to consider the ethical implications. Will you track everything about an employee? Some software companies allow you to follow an employee anywhere they go by their ID badge. Other startups can tell you what’s on your employees’ screens at any given time, what tone they are using on a conference call, or how long they spend in the bathroom.
While this type of data seems interesting, its effect on employee engagement could be disastrous. Be careful as you consider your data gathering policies and post a data ethics policy, so every employee knows what to expect when it comes to the data your organization is gathering from and about them!
Consider this article from the Wall Street Journal
“The New Ways Your Boss Is Spying on You”
While the landmines are there, navigating them is well worth the effort. The power of HR data to transform the HR function into a key strategic business partner is tremendous. But, don’t wait to get started. Effective data strategies take years to build. Now is the time to lay the groundwork for a digital harvest in the future.
The fishing metaphor is timely and applicable. You must get your line in the water if you are ever going to catch a fish. Get a line in the water today by following the recommendations contained in this playbook. For more information, please visit us at decisionwise.com. We have several consultants ready to assist you in your HR data efforts.
GOOD LUCK!



